1. Introdução
Esse artigo tem como finalidade explicar como analisar um servidor de aplicação ou banco de dados e identificar possíveis falhas através de um rápido diagnóstico. O objetivo é que em 05 minutos você tenha descartado ou confirmado se a falha no aplicativo está associada à infraestrutura e qual o ativo.
Ou seja, o objetivo é através de contadores básicos, identificarmos se há um afunilamento de recursos no Servidor que hospeda a aplicação e caso sim, quem é o responsável por esse afuniliamento.
2. Estratégia
Antes de iniciar, tenha sempre alguns conceitos bem firmados em mente para que sua análise seja rápida e objetiva! Tenha em mente esses 04 conceitos abaixo:
Conceito 1: 90% dos incidentes são coisas simples de se diagnosticar.
Não queria ser um Físico Quântico que é parecido com um cego num quarto escuro à procura de um gato preto que não está lá.

Tenha em mente que você precisará analisar todos os servidores que compõem a estrutura de sua aplicação.
Conceito 2: Nenhum erro é igual ao outro, por mais que os sintomas sejam parecidos, sempre inicie sua análise do marco zero novamente.

Conceito 3: Lembre-se que a maioria dos incidentes são efeito dominó.

Ou seja, algo falhou por outro que falhou, que outro que falhou, e assim sucessivamente.

Por exemplo, lock em banco de dados normalmente é ocasionado por má execução de querys ou store procedures e concorrências ocasionadas pela aplicação, ou pouco recurso no servidor mesmo.
Consumo excessivo de memória pode estar sendo ocasionado por um vazamento (memory leak), ou bug na aplicação, bem como falta mesmo de recurso de memória no servidor.
Conceito 04: Entender a aplicação e o que analisar
Saiba como a aplicação funciona, o que acessa o que, onde os dados são armazenados, quais as melhores práticas de configuração, onde os logs de operação estão armazenados e como interpretar eles, como a aplicação é constituída, por exemplo: Web Services, Windows Services, armazenamento em disco e armazenamento em banco de dados, etc. Quais os aplicativos de terceiros e recursos do sistema operacional que sua aplicação utiliza, por exemplo .NET Framework, Java, Internet Information Services, SNMP, etc.
Assim você poderá estender sua análise corretamente inclusive entender “o que afeta o que”.
3. Passos
Primeiro Passo: Diagnóstico e Desempenho do Servidor (Tempo de Identificação: 180 segundos)
Abra o Monitor de Desempenho digitando “perfmon” no executar do Windows.
Em seguida vá Desempenho – Sistema e Inicie o Contador “System Diagnostics”
Inicie e espere a coleta, leva em média 60 segundos, e o tempo máximo é de 10 minutos (tolerância).
Em seguida abra o Relatório Diagnóstico gerado para interpretação.
Diagnóstico de Saúde
Observe o Relatório abaixo e veja que a parte de Diagnóstico teve um alerta, referente a o UAC estar desativado e o Servidor não possuir nenhum antivirus instalado. Os demais itens estão OK.
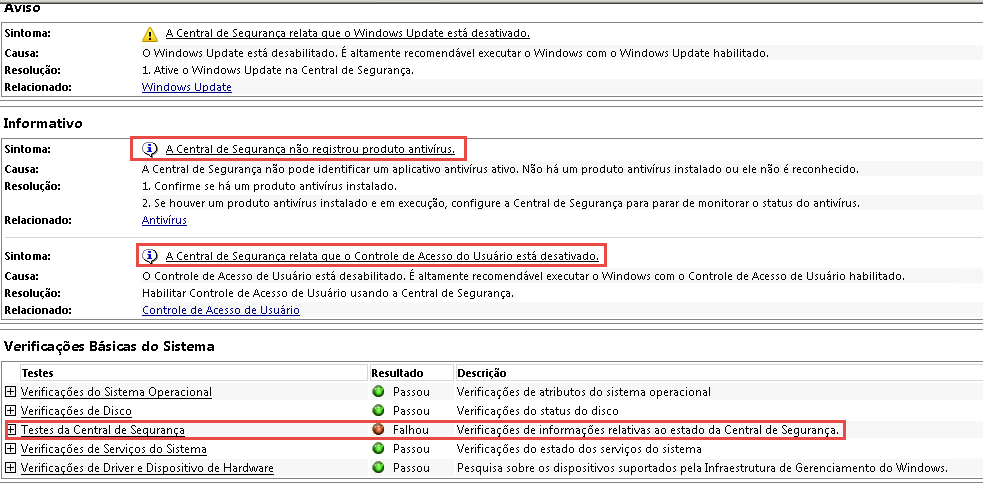
Caso algum componente apresente uma falha, o Diagnóstico irá informar e detalhar, com por exemplo problemas de bit sujo no disco indicando corrupção.
Diagnóstico de Desempenho
Dentro ainda do mesmo relatório, vamos avaliar agora se temos problemas relacionados à Desempenho.

Os itens que devemos sempre observar são: Processador, Memória, Disco e Rede. Se há algum afunilamento neles e caso haja, quem está causando o mesmo (Processo).
Nesse relatório, caso algum dos itens esteja com afunilamento, ele ficará com um STATUS em vermelho. No nosso caso, todos os itens estão OK, sendo que todos estão ociosos e a memória está com status normal. Vamos ver no detalhe a memória. Para isso, no mesmo relatório, clique em Memória.
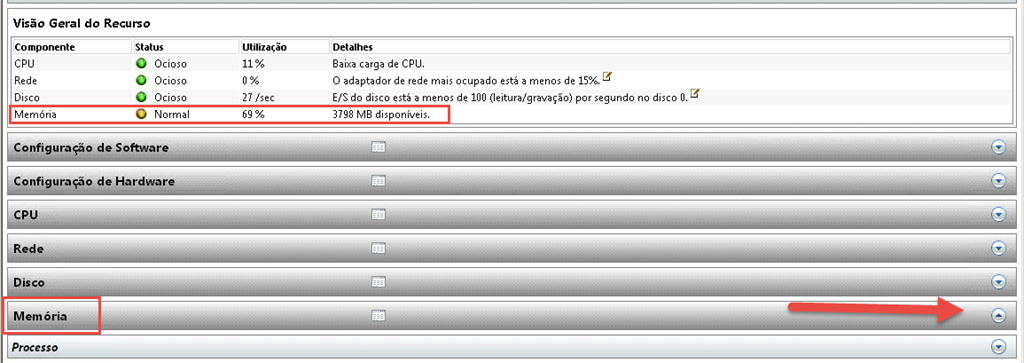
Podemos observar no detalhe, quais os processos estao consumindo mais memória e identificar se um processo de nossa aplicação está consumindo memória de forma anormal, ou se algum processo de um aplicativo de terceiro que nossa aplicação dependa está tendo um consumo anormal, ou se é apenas falta de memória no servidor mesmo.
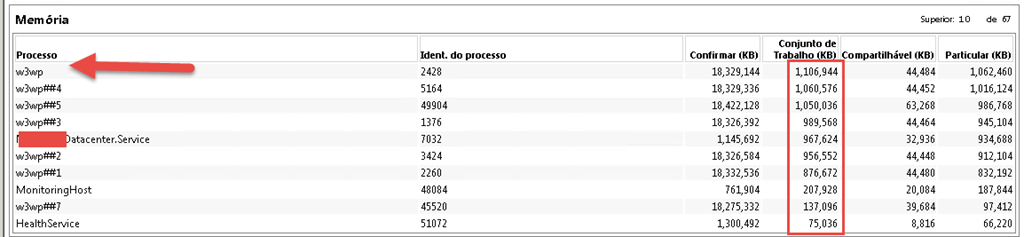
Inclusive é possivel identificar os contadores separados, mas isso é para uma análise mais complexa. Nosso objetivo aqui é uma análise em 05 minutos para identificar possíveis afunilamentos de recursos e os responsáveis pelo mesmo.
Lembre-se de executar esse procedimento em cada servidor que faz parte da aplicação. Caso não possua acesso, solicite ao time responsável a geração do relatório e encaminhamento do mesmo a você. De preferência executar a análise no momento do incidente. Outro ponto importante, ative essas coletas remotamente ao mesmo tempo, conectando no servidor e ativando.
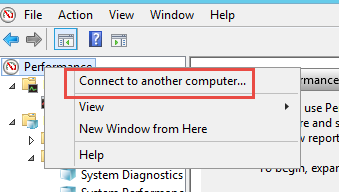
Segundo Passo: Diagnóstico de Eventos (Tempo de Identificação: 120 segundos)
Outro diagnóstico importante de ser feito e fácil de identificar são os eventos gerados pelo Sistema Operacional e Aplicativo. Neles é possivel identificar falhas relacionadas ao ambiente e aplicativo e comparar com o diagnóstico feito no primeiro passo e com logs gerados pela aplicação.
Para isso, abra o Visualizador de Eventos no Servidor digitando o comando eventvwr no executar do seu servidor.
Em seguida a parte mais simples. Comparar os horários que ocorrem as falhas com possíveis eventos, momentos antes ou depois do incidente.
Comparar:
Evento de Aplicativos, inclusive se há eventos por exemplo relacionandos ao Internet Information Services, .NET Framework, JAVA Runtime, Banco de Dados.
Eventos de Sistema, se há erros relacionados a leitura no disco, falha de processamento, parada inesperada de um serviço.
Comparar esses eventos a coleta feita pelo Perfmon mais os logs da sua aplicação.
Lembrando novamente que o objetivo é apenas identificar a falha, para depois entender o motivo que ocasiona ela. Descobrindo a falha, você poderá tomar ações rápidas para contornar o incidente até sua soluçao final. Por exemplo:
– Reinício do Internet Information Services
– Reinício de um serviço da aplicação
Entre outras ações de rapido resultado.
4. Conclusão
Esses templates estao disponíveis nativamente no Windows Server 2008 e Windows Server 2012, bem como nos Windows Clientes (Windows 8 e Windows 10).
O objetivo é uma análise rapida em cima de um ambiente e aplicação para entender o que está impactando o funcionamento. Caso os passos não resolvam, iremos para uma análise mais profunda que envolve:
– Processos
– Contadores Específicos
– Ferramentas Adicionais (Sysinternals, Management Studio do SQL, etc.) mas ficará para um próximo artigo!